




Imagine having a specialized system that can answer your questions about Python programming instantly and accurately. While traditional approaches often rely on keyword matching and can be limited in their understanding of natural language, recent advancements in machine learning offer a more sophisticated solution: semantic search.
By combining the text embeddings, large language models (LLMs), and approximate nearest neighbor search algorithms, we can build Q&A systems that truly understand the meaning behind user queries and provide relevant, context-aware answers.
Let's dive into the details of how to build such a system, step by step.
The core of our Q&A system relies on a robust semantic search approach. This involves several key stages:
Data Preparation:

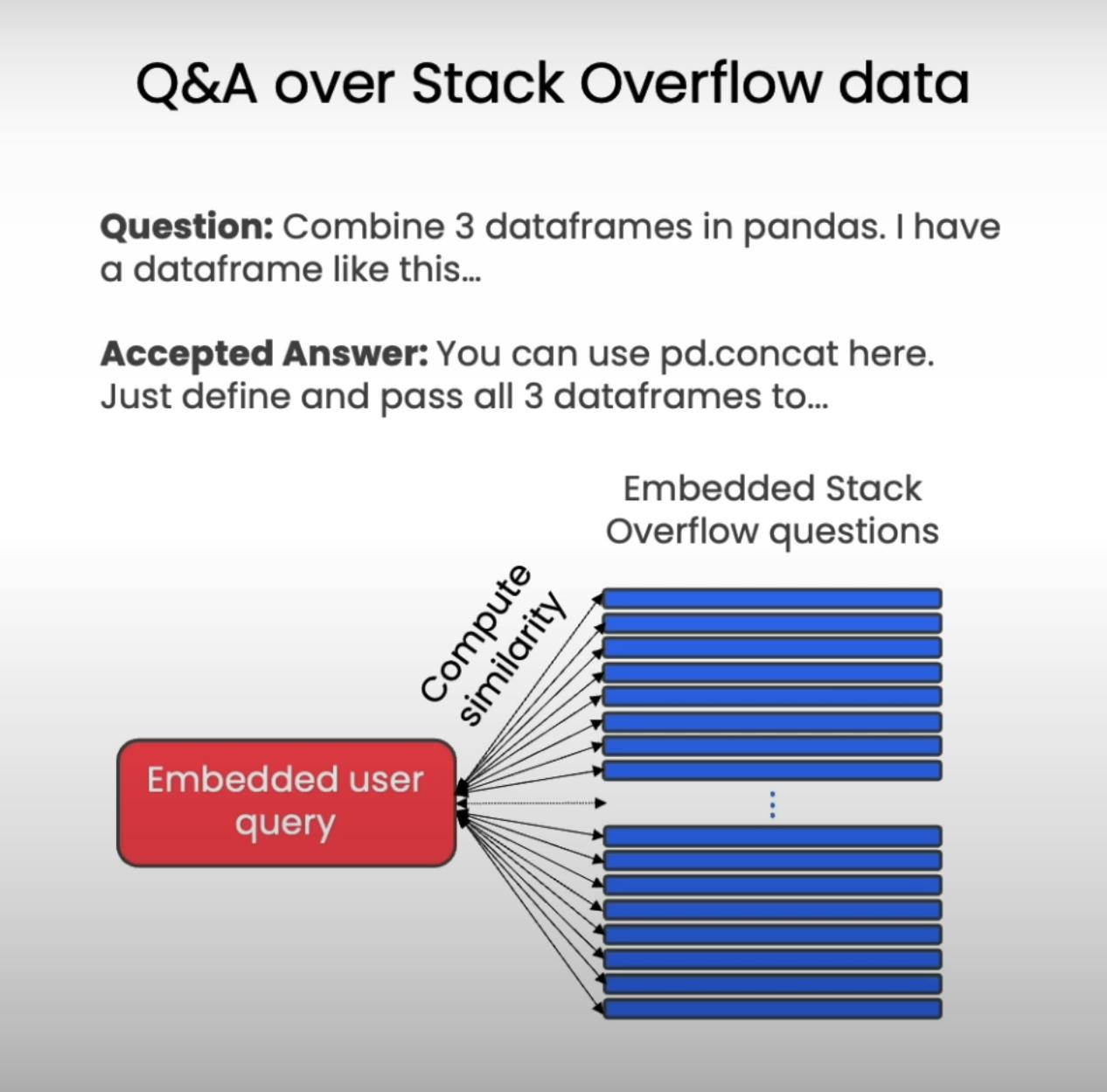
First, we need a relevant dataset to train and test our system. For this example, we'll use Stack Overflow posts, a reliable source of questions and answers related to programming. This dataset contains questions, their corresponding accepted answers, and the programming language (e.g., Python).
Next, we use text embeddings. These embeddings are vector representations of text that capture the semantic meaning of words and sentences. By converting questions into embeddings, we can compare them based on their meaning rather than just surface-level keyword matches.
We use a pre-trained text embedding model (e.g., text-embedding-gecko) to generate embeddings for all the questions in our dataset. This process can be computationally intensive, so pre-computing and storing these embeddings beforehand significantly improves efficiency when responding to user queries.
Here's an example code snippet demonstrating how to pre-compute and store question embeddings using the vertexai library:
from vertexai.language_models import TextEmbeddingModel
# Load the pre-trained embedding model
embedding_model = TextEmbeddingModel.from_pretrained("textembedding-gecko@001")
# Extract questions from the DataFrame
so_questions = so_database.input_text.tolist()
# Encode questions into embeddings (batched for efficiency)
question_embeddings = encode_text_to_embedding_batched(
sentences=so_questions,
api_calls_per_second=20/60,
batch_size=5
)
# Save the embeddings for future use
import pickle
with open('question_embeddings.pkl', 'wb') as file:
pickle.dump(question_embeddings, file)
This code first loads the pre-trained textembedding-gecko model. Then, it extracts the questions from the Stack Overflow DataFrame and converts them into a list. The encode_text_to_embedding_batched function (implementation details omitted for brevity) efficiently encodes the questions into embeddings while managing API call limits. Finally, the embeddings are saved as a pickle file for later use.
Remember to replace "textembedding-gecko@001" with the appropriate model name and adjust the API call parameters as needed.
Note: This snippet focuses on pre-computing embeddings. The full data preparation process would also involve loading the Stack Overflow dataset and performing data cleaning and pre-processing steps.
User Query Processing:
Now that we have a database of embedded questions, how do we handle a user's query? The process is quite similar:
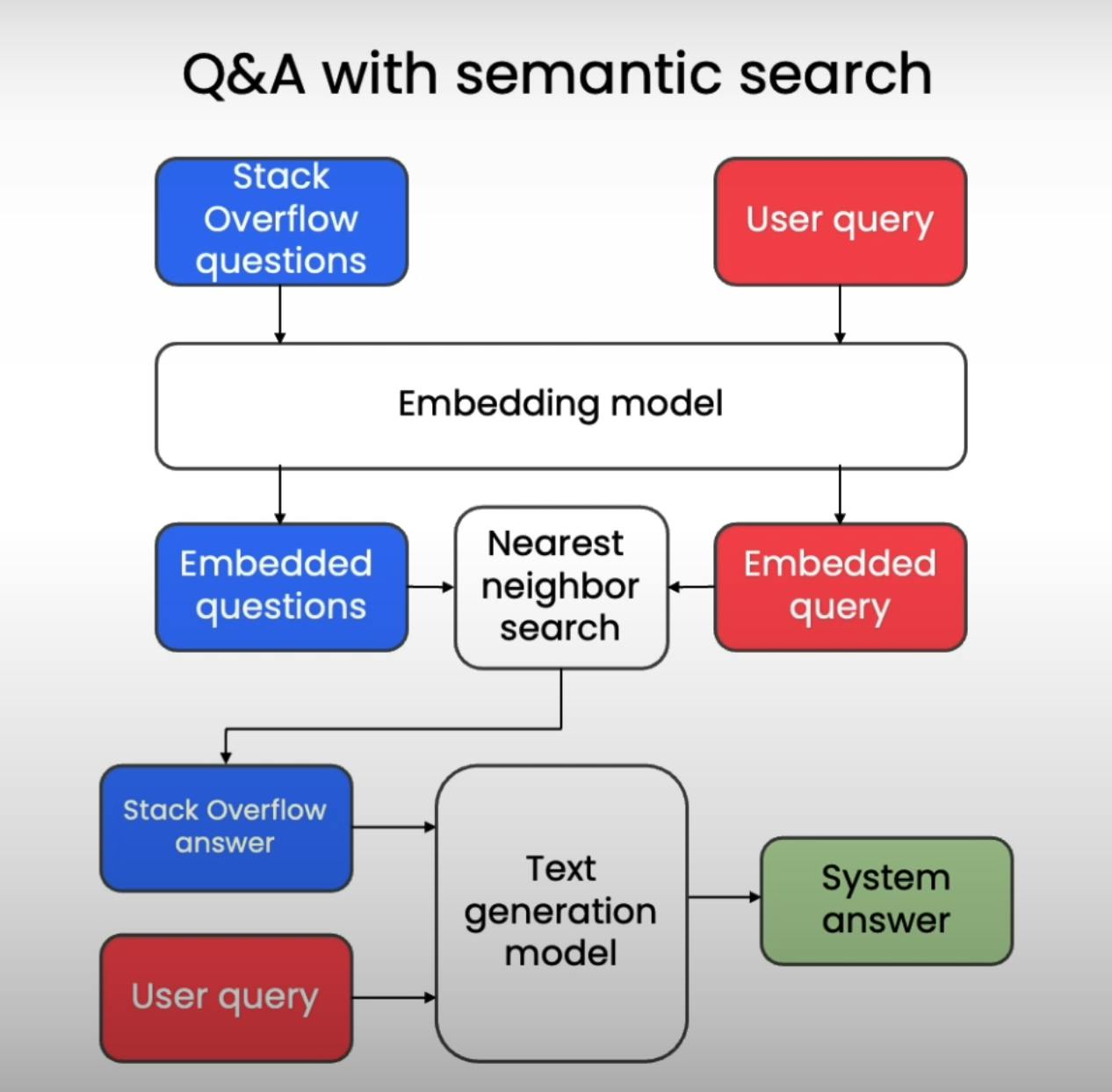
Embed the user query: We use the same text embedding model to convert the user's question into an embedding vector. This ensures consistency and allows for meaningful comparison with the existing question embeddings.
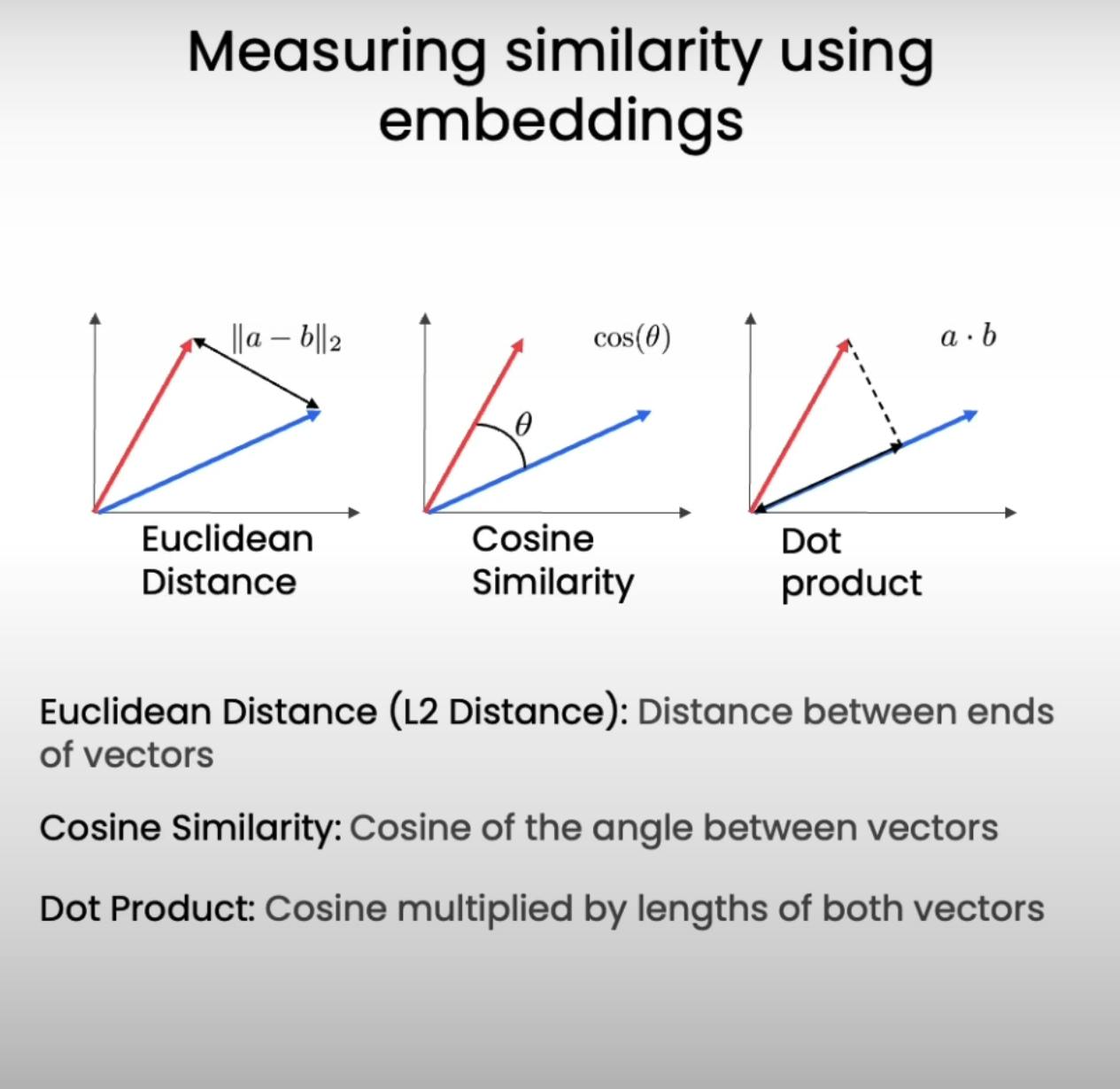
Calculate cosine similarity: We calculate the cosine similarity between the user's query embedding and each of the question embeddings in our database. Cosine similarity measures the angular distance between two vectors, with a higher value indicating greater similarity in meaning.
Nearest neighbor search: We identify the question in the database with the highest cosine similarity score. This question is considered the "nearest neighbor" to the user's query in the semantic space.
By using cosine similarity and nearest neighbor search, we can identify questions that are semantically similar to the user's query, even if they don't share the exact same words. This allows our Q&A system to understand the user's intent and provide more relevant answers.
Here's how you can find the most similar question in the database using cosine similarity and nearest neighbor search:
from sklearn.metrics.pairwise import cosine_similarity
# User query
query = "How to concatenate dataframes in pandas?"
# Embed the query
query_embedding = embedding_model.get_embeddings([query])[0].values
# Calculate cosine similarity with all question embeddings
cos_sim_array = cosine_similarity([query_embedding], list(so_database.embeddings.values))
# Find the index of the most similar question
index_doc = np.argmax(cos_sim_array)
# Print the most similar question and its similarity score
print(f"Most similar question: {so_database.input_text[index_doc]}")
print(f"Cosine similarity: {cos_sim_array[0][index_doc]}")
Example Output:
Most similar question: Add a column name to a panda dataframe (multi index)<p>I concatenate series objects, with existing column names together to a DataFrame in Pandas...
Cosine similarity: 0.7782096307231192
This code snippet first embeds the user's query. Then, it calculates the cosine similarity between the query embedding and all the question embeddings stored in the so_database DataFrame. Finally, it identifies the index of the question with the highest similarity score and prints both the question and its similarity score.
Remember that this snippet assumes you have already pre-computed and loaded the question embeddings as described in the previous section.
Answer Generation:
Once we've identified the most similar question in our database, we can extract its corresponding answer. However, simply presenting this raw answer to the user might not be the most helpful or engaging experience. This is where large language models (LLMs) come into play.
We can use an LLM to refine the extracted answer by providing it with a prompt that includes:
The user's original query: This helps the LLM understand the specific context and intent of the user.
The extracted answer from the database: This provides the LLM with the relevant information to formulate a response.
By combining these elements in the prompt, we guide the LLM to generate a response that is not only informative but also tailored to the user's specific question and context. This results in a more natural and engaging Q&A experience.
Here's how you can use an LLM to generate a conversational response based on the extracted answer:
from vertexai.language_models import TextGenerationModel
# Load the LLM
generation_model = TextGenerationModel.from_pretrained("text-bison@001")
# User query
query = "How to concatenate dataframes in pandas?"
# Create context with user query and extracted answer
context = f"Question: {query}\nAnswer: {so_database.output_text[index_doc]}"
# Define the prompt
prompt = f"""Here is the context: {context}
Using the relevant information from the context, provide a concise and informative answer to the user's question.
"""
# Generate response
response = generation_model.predict(prompt=prompt, temperature=0.2, max_output_tokens=1024)
# Print the response
print(response.text)
Example Output:
To concatenate dataframes in pandas, you can use the `concat()` function. This function allows you to combine dataframes along either rows (axis=0) or columns (axis=1).
This code snippet first loads the text-bison LLM. Then, it creates a context string containing the user's query and the extracted answer. This context is incorporated into a prompt that instructs the LLM to generate a concise and informative response. Finally, the LLM generates the response, which is printed as output.
Remember to replace "text-bison@001" with the appropriate model name and adjust the temperature and max_output_tokens parameters as needed.
Handling Irrelevant Results:
While semantic search significantly improves the accuracy of Q&A systems, there's still a chance that the most similar question in the database might not be truly relevant to the user's query. For example, if the user asks about "making the perfect lasagna," and the closest match in our Stack Overflow database is about "concatenating dataframes in pandas," the provided answer wouldn't be helpful.
To address this, we can further leverage the capabilities of LLMs. We can modify the prompt to instruct the LLM to identify and handle irrelevant matches. Here's how:
Include an "irrelevant match" instruction: In the prompt, we explicitly tell the LLM to respond with a specific message (e.g., "I couldn't find a good match...") if the context doesn't provide relevant information to answer the user's query.
LLM evaluation: The LLM analyzes the context and compares it to the user's query. If it determines that the extracted answer isn't relevant, it follows the provided instruction and generates the "no good match" response.
This approach allows our Q&A system to be more robust and user-friendly. Instead of providing an incorrect or irrelevant answer, it acknowledges the lack of a good match and informs the user accordingly.
Here's how you can modify the prompt to handle irrelevant matches:
# ... (previous code for embedding, similarity calculation, and answer extraction)
# Define the prompt with "irrelevant match" instruction
prompt = f"""Here is the context: {context}
Using the relevant information from the context, provide a concise and informative answer to the user's question.
If the context doesn't provide any relevant information, answer with:
[I couldn't find a good match in the document database for your query.]
"""
# ... (rest of the code for LLM prediction and printing the response)
Example Output (for an irrelevant query):
I couldn't find a good match in the document database for your query.
By adding the "irrelevant match" instruction to the prompt, the LLM can now identify and handle cases where the extracted answer isn't relevant to the user's query. This results in a more informative and user-friendly Q&A experience.
Scaling with Approximate Nearest Neighbor Search:

Our Q&A system works well with a small dataset like the one used in this example. However, when dealing with massive databases containing millions or even billions of documents, the exhaustive search for nearest neighbors becomes computationally expensive and time-consuming.
To address this challenge, we can utilize approximate nearest neighbor (ANN) search algorithms. These algorithms sacrifice a small degree of accuracy for significant gains in efficiency. They quickly identify a set of documents that are very likely to be the nearest neighbors without exhaustively comparing the query to every single document in the database.
One popular ANN algorithm is ScaNN (Scalable Nearest Neighbors). ScaNN utilizes a combination of quantization, clustering, and graph-based search techniques to efficiently find nearest neighbors in high-dimensional spaces.
By integrating ScaNN into our Q&A system, we can significantly improve its scalability and performance when dealing with large datasets. This allows us to handle real-world applications where efficiency is crucial.
Here's how you can use ScaNN to find the nearest neighbor for a user query:
import scann
import time
# ... (previous code for embedding and data preparation)
query = "how to concat dataframes pandas"
# Create a ScaNN index
index = scann.scann_ops_pybind.builder(question_embeddings, 10, "dot_product").tree(
num_leaves=200, num_leaves_to_search=10, training_sample_size=250000
).score_ah(2, anisotropic_quantization_threshold=0.2).build()
start = time.time()
query_embedding = embedding_model.get_embeddings([query])[0].values
neighbors, distances = index.search(query_embedding, final_num_neighbors = 1)
end = time.time()
for id, dist in zip(neighbors, distances):
print(f"[docid:{id}] [{dist}] -- {so_database.input_text[int(id)][:125]}...")
print("Latency (ms):", 1000 * (end - start))
[docid:1143] [0.778209388256073] -- Add a column name to a panda dataframe (multi index)<p>I concatenate series objects, with existing column names together to a...
Latency (ms): 79.4184970855713
This code snippet first creates a ScaNN index using the pre-computed question embeddings. The scann_ops_pybind.builder function allows you to configure various parameters of the index, such as the number of leaves in the tree and the similarity metric used. Then, the search method is used to find the nearest neighbor for the user's query embedding. Finally, the nearest neighbor and its distance are printed as output.
Note: This snippet assumes you have installed the scann library and have pre-computed the question embeddings.
By replacing the exhaustive search with ScaNN, you can achieve significant performance improvements (upto 10x), especially when dealing with large datasets.
Conclusion:
The combination of semantic search and LLMs offers a useful approach to building intelligent Q&A systems. By understanding the meaning behind user queries and generating context-aware responses, these systems can provide a more natural and engaging experience for users. Additionally, the use of approximate nearest neighbor algorithms allows for efficient scaling to handle large datasets, making this approach suitable for real-world applications.