




Imagine unleashing an LLM without proper safeguards in place – it could be like letting a mischievous AI genie out of its bottle, with no telling what kind of unintended (and potentially harmful) consequences might arise. That's why LLM safety is so crucial. Monitoring for offensive or factually incorrect outputs, to crafting prompts that align with your model's training data and setting confidence thresholds that uphold your values.
Deployment: Batch or Real-Time?
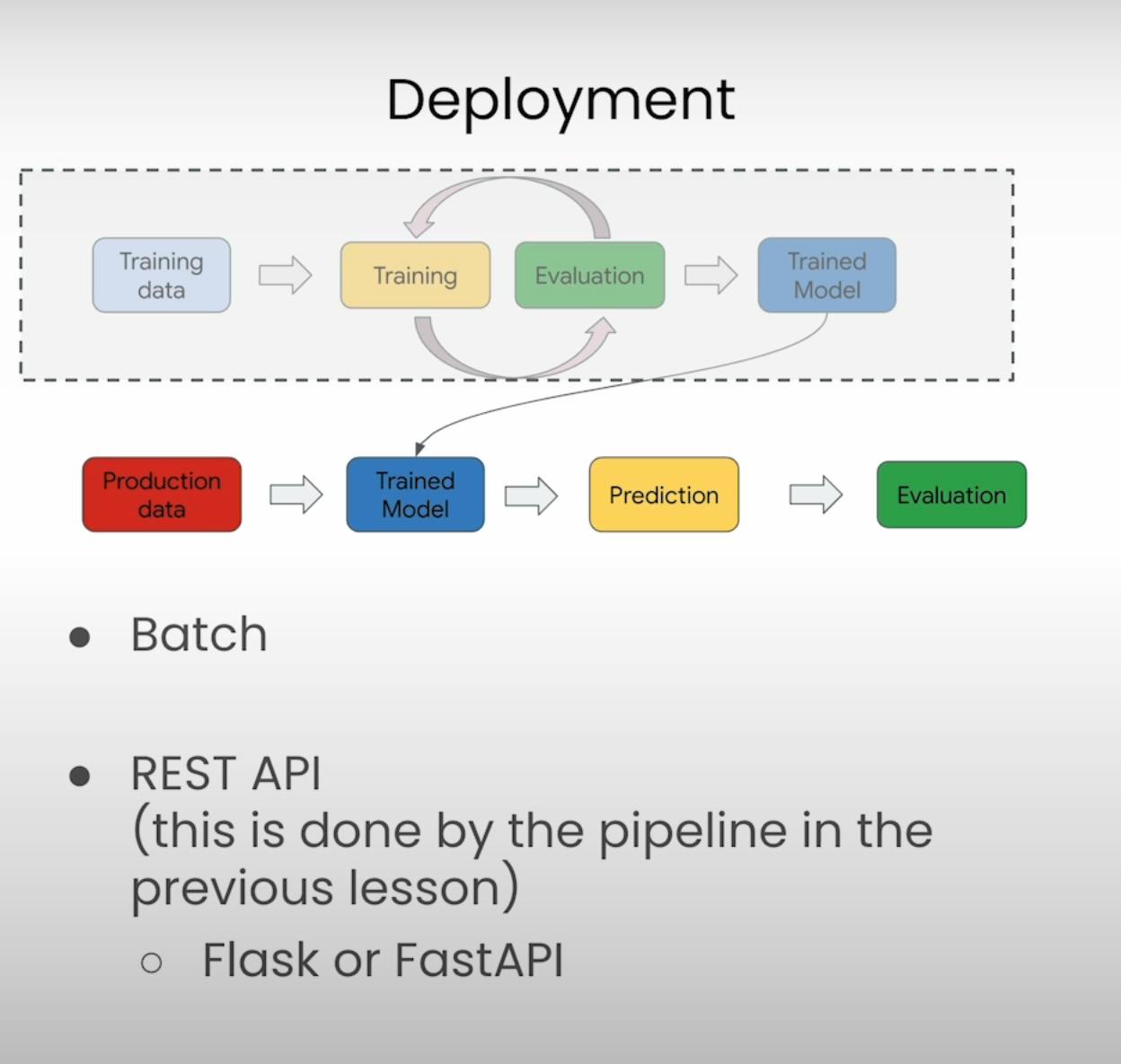
Imagine you're part of a team developing a killer app that analyzes customer reviews for a major e-commerce site. You've trained a machine learning model to detect positive or negative sentiment in these reviews, but now comes the tricky part: deployment. How do you get this up and running in the real world?
Well, you've got two main options: batch deployment or real-time REST API deployment. Let's break 'em down, shall we?
Batch Deployment
Picture this: you've got a massive pile of customer reviews waiting to be analyzed. With batch deployment, you can take your trained model and let it loose on all those reviews at once, in real time. This can be a scheduled process, so you don't need real-time responsiveness. You can batch all the reviews together, send 'em to your model, and get predictions on whether they're positive or negative.
REST API Deployment: Real-Time
Now, let's say you're building a fancy chat application that answers Stack Overflow-style coding questions in real-time. In this case, you need your model to be online and accessible as an API. When a user asks a question, the request gets sent to your API, your model does its thing and the user gets an answer.
For this kind of real-time use case, you'd deploy your model as a REST API, potentially using libraries like Flask or FastAPI to package it up all nice and snug in a container.
To get started, we'll need to initialize the Vertex AI SDK with our project ID, region, and credentials:
import vertexai
from utils import authenticate
credentials, PROJECT_ID = authenticate()
REGION = "us-central1"
vertexai.init(project=PROJECT_ID,
location=REGION,
credentials=credentials)
Keeping an Eye on Your Model: Monitoring, Scalability, and Latency
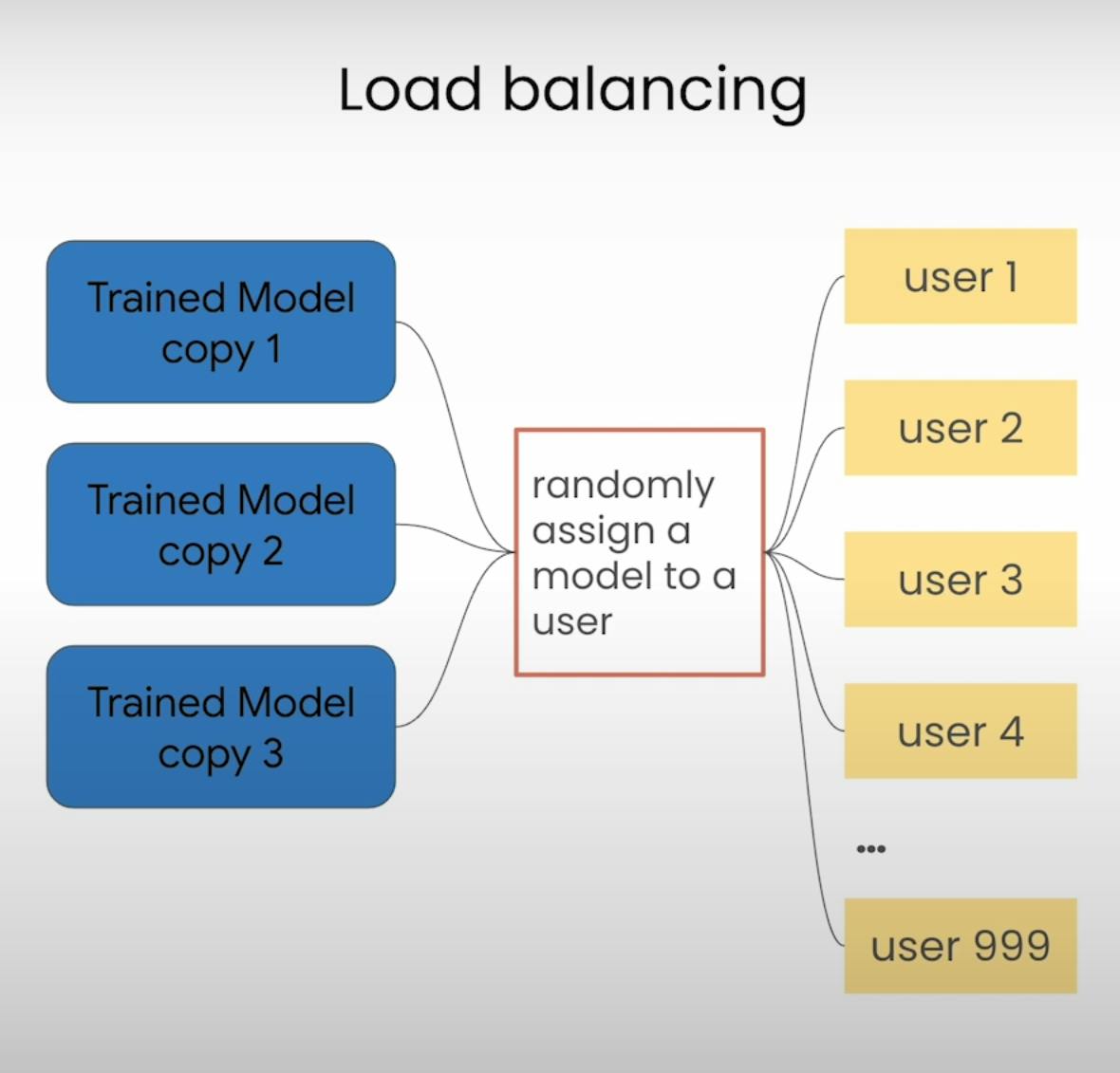
Okay, so you've got your model deployed and running smoothly. But wait, there's more! you've got to keep an eye on a few crucial factors:
Model Monitoring: You'll want to keep track of operational metrics, performance evaluation, and even monitor for potential safety issues or bias.
Scalability and Load Testing: What happens when your app goes viral, and suddenly everyone wants to use it? You'll need to make sure your model can handle the load. Load testing is needed here, it lets you see how your API handles a flood of requests.
Latency Considerations: Imagine you're using your chat app, and you have to wait 10 minutes for an answer. Talk about a buzzkill! That's why you'll want to set a threshold for permissible latency. Is two seconds too long? What about 100 milliseconds? It's all about finding that sweet spot between performance and user experience.
And if your latency is a little too high? No worries, you've got options! You could try out a smaller language model, deploy on faster GPUs for a speed boost, or even move your model to a region closer to your users. These tricks can optimize your AI's reaction time.
Training Data & Production Data

Alright, let's talk about something crucial: consistency between your training data and production data. See, your model was trained on a specific type of data format, like prompts with an instruction and a question. But what if, in production, you're only sending questions without instructions? That's a recipe for disaster!
Imagine you're training a virtual assistant to help you with your daily tasks. During training, you give it examples like "Please remind me to walk the dog at 6 PM" or "Can you add 'buy milk' to my grocery list?" But then, in real life, you start giving it commands like "Walk the dog" or "Milk." Your poor virtual assistant would be completely confused.
To avoid this mismatch, you'll need to make sure your production data is consistent with your training data. In our coding example, we added the instruction back to the question, creating a prompt that matched the format the model was trained on:
INSTRUCTION = """\
Please answer the following Stackoverflow question on Python.\
Answer it like\
you are a developer answering Stackoverflow questions.\
Question:
"""
QUESTION = "How can I store my TensorFlow checkpoint on\
Google Cloud Storage? Python example?"
PROMPT = f"""\
{INSTRUCTION} {QUESTION}
"""
This ensures smooth communication and top-notch performance.
Now, let's get our model loaded:
from vertexai.language_models import TextGenerationModel
model = TextGenerationModel.from_pretrained("text-bison@001")
deployed_model = TextGenerationModel.get_tuned_model(tuned_model_select)
With our deployed model and prompt set, we can call the API and get our response:
response = deployed_model.predict(PROMPT)
output = response._prediction_response[0][0]["content"]
print(output)
To store your TensorFlow checkpoint on Google Cloud Storage, you can use the tf.io.gfile.GFile class. This class provides a way to read and write files to Google Cloud Storage.
To save a checkpoint to Google Cloud Storage, you can use the following code:
import tensorflow as tf
from tensorflow.io import gfile
# Create a checkpoint directory in Google Cloud Storage.
checkpoint_dir = gfile.GFile('gs://my-bucket/my-checkpoint-dir', 'w')
# Save the checkpoint to Google Cloud Storage.
Monitoring for Harmful Content

Now, let's talk about something really important: safety. See, large language models are incredibly useful, but they can also generate offensive, insensitive, or factually incorrect content if we're not careful.
That's where safety attribute scoring comes in. It's like having a built-in filter that checks your model's output for potential harm. You can set thresholds for different safety categories, like "dangerous content" or "hate speech," and define what probability scores are acceptable for your use case.
safety_attributes = response._prediction_response[0][0]['safetyAttributes']
pprint(safety_attributes)
This will give you an output like:
{'blocked': False,
'categories': ['Finance', 'Insult', 'Politics', 'Sexual'],
'safetyRatings': [{'category': 'Dangerous Content',
'probabilityScore': 0.1,
'severity': 'NEGLIGIBLE',
'severityScore': 0.1},
{'category': 'Harassment',
'probabilityScore': 0.1,
'severity': 'NEGLIGIBLE',
'severityScore': 0.1},
{'category': 'Hate Speech',
'probabilityScore': 0.0,
'severity': 'NEGLIGIBLE',
'severityScore': 0.1},
{'category': 'Sexually Explicit',
'probabilityScore': 0.1,
'severity': 'NEGLIGIBLE',
'severityScore': 0.0}],
For example, let's say your model generates a response with a 0.5 probability score for "hate speech." You might decide that's too risky and choose to filter out that response. Or, if the severity score is low, you might deem it acceptable. It's all about finding that sweet spot that aligns with your values and the needs of your users.
And then there's citation metadata – a fancy way of checking if your model is just regurgitating existing content or actually generating something original.
citation = response._prediction_response[0][0]['citationMetadata']['citations']
pprint(citation)
If your model is citing sources, you'll see something like:
[{'endIndex': 192.0,
'publicationDate': '1785',
'startIndex': 0.0,
'title': 'Hamlet. By Will. Shakspere. Printed Complete from the Text of Sam. '
'Johnson and Geo. Steevens, and Revised from the Last Editions'}]
Otherwise, you'll get an empty list, which means your model is generating original content.
Putting It All Together: A Real-World Example
Alright, let's bring all these concepts together with a real-world example. Imagine you're part of a team building a Stack Overflow-style Q&A app for Python developers. You've trained a language model on a dataset of Python questions, complete with instructions and answers.
When it's time to deploy, you set up a REST API so users can get real-time responses to their coding conundrums. But wait, you remember the importance of consistency! So, you make sure to combine the instruction with the user's question, creating a prompt that matches your training data format.
As responses start rolling in, you keep a close eye on the safety attributes. If a response has a high probability score for "dangerous content," you might decide to filter it out or flag it for review.
With all the right checks and balances in place to ensure your users get safe, accurate, and original responses every time.
Wrapping It Up
By understanding the intricacies of model deployment, consistency between training and production data, and the importance of safety attributes, we can build AI systems that are not only powerful but also trustworthy and ethical.