


Detecting Hallucinations in Large Language Models with Text Similarity Metrics


In the world of LLMs, there is a phenomenon known as "hallucinations." These hallucinations are inaccurate or irrelevant responses to prompts. In this blog post, I'll go through hallucination detection, exploring various text similarity metrics and their applications. I'll dive into the details of each approach, and discuss their strengths and limitations. I'll dive into practical considerations and acknowledge the limitations of relying solely on automated metrics.
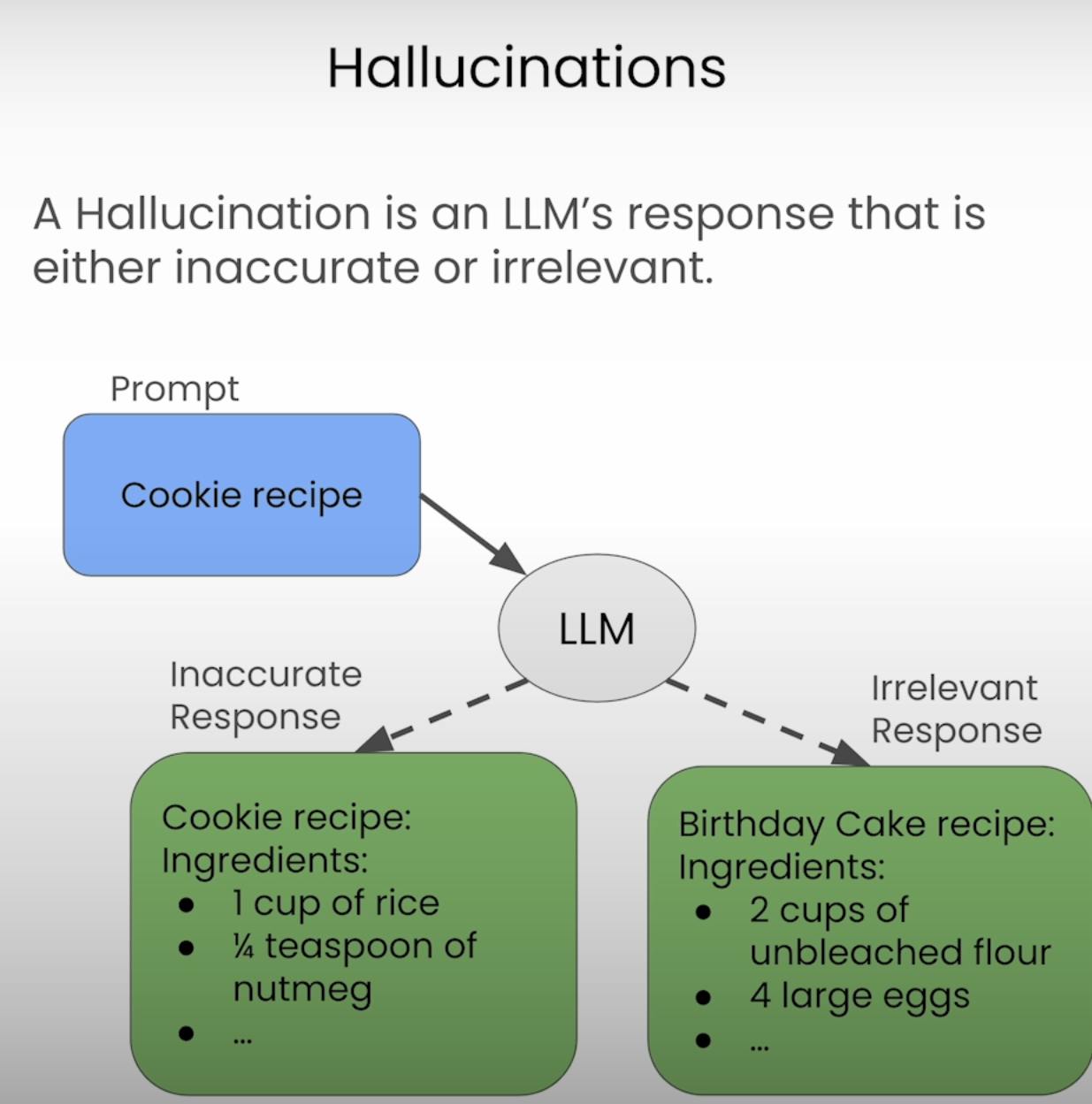
Text Similarity Metrics for Hallucination Detection
BLEU Score
The BLEU (Bilingual Evaluation Understudy) score has been used for natural language processing for a long time, especially for machine translation. This metric relies on similarities across the same tokens, comparing the exact text of the prompt and response.
To calculate the BLEU score, we first capture essential information, such as the prompt and response pair. Then, the metric compares the presence of unigrams (single tokens), bigrams (pairs of words), trigrams, and higher-order n-grams between the prompt and response. These comparisons are weighted and combined to produce a score between 0 and 1, with higher scores indicating greater similarity.
from evaluate import load
blue = load("blue")
prompt = "In this lesson, we will detect hallucinations in our data,..."
response = "Hallucinations in data represent inaccurate or irrelevant responses to prompts..."
blue_score = blue.compute(predictions=[response], references=[[prompt]])
While BLEU scores have their merits, they also come with limitations. The scores can vary significantly depending on the dataset, making it challenging to establish universal thresholds. Additionally, they rely solely on token-level comparisons, potentially overlooking semantic similarities.
from whylogs.util import WhyLogs
from whylogs.metrics import BleuScore
wl = WhyLogs()
@wl.register_metric("bleu_score")
def bleu_score(text):
return [blue.compute(predictions=[text["response"]], references=[[text["prompt"]]])["blue"]]
annotated_chats = wl.applyUDFsFromSchema(CHATS_DATASET)
annotated_chats.groupby("bleu_score").count().reset_index().sort_values("bleu_score", ascending=True).head(10)
By visualizing the BLEU score distribution and analyzing low-scoring examples, we can shortlist potential hallucinations. However, it's necessary to remember that low BLEU scores do not necessarily imply hallucinations; they may simply indicate a difference in phrasing or semantics.
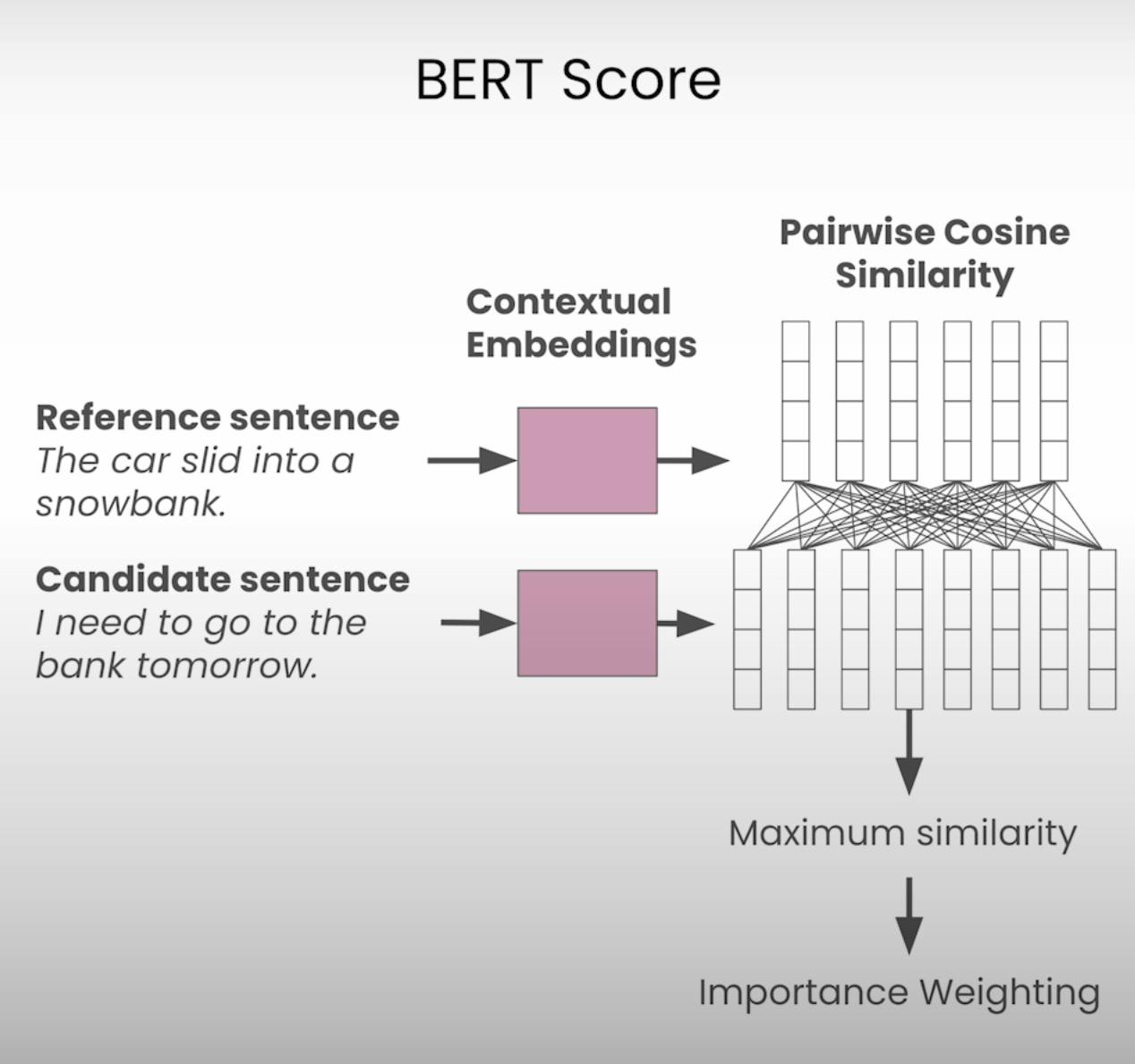
BERT Score
Unlike the BLEU score, which focuses on token-level comparisons, the BERT score utilizes contextual embeddings to capture semantic similarities between words. This approach leverages pre-trained language models, such as BERT (Bidirectional Encoder Representations from Transformers), to represent words in their respective contexts.
from evaluate import load
bert_score = load("bert")
prompt = "In this lesson, we will detect hallucinations in our data,..."
response = "Hallucinations in data represent inaccurate or irrelevant responses to prompts..."
bert_result = bert_score.compute(predictions=[response], references=[prompt])
By calculating the pairwise cosine similarity between the embeddings of each word in the prompt and response, the BERT score provides a more nuanced measure of semantic similarity. This approach can be particularly useful when dealing with paraphrased or rephrased responses, where the exact token match may be low but the overall meaning remains intact.
from whylogs.util import WhyLogs
from whylogs.metrics import BERTScore
wl = WhyLogs()
@wl.register_metric("bert_score")
def bert_score(text):
bert = load("bert")
result = bert.compute(predictions=[text["response"]], references=[text["prompt"]])
return [result["f1"]]
annotated_chats = wl.applyUDFsFromSchema(CHATS_DATASET)
annotated_chats[annotated_chats["bert_score"] < 0.5].head(10)
By visualizing the BERT score distribution and analyzing low-scoring examples, we can uncover potential hallucinations where the response deviates significantly from the semantic meaning of the prompt. However, it's important to note that even with BERT scores, there may be instances where a valid response receives a low score due to divergent topics or contexts between the prompt and response.
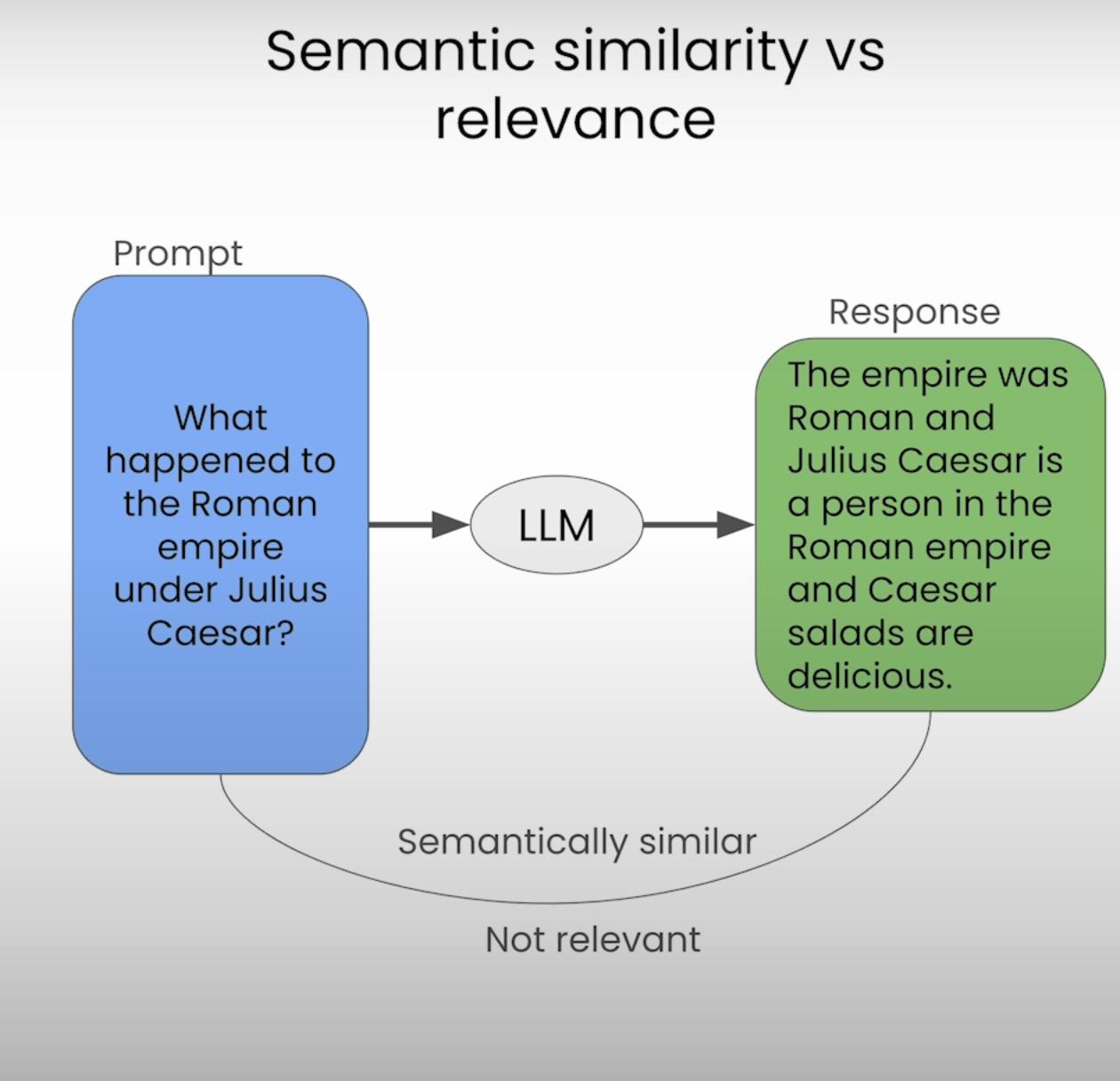
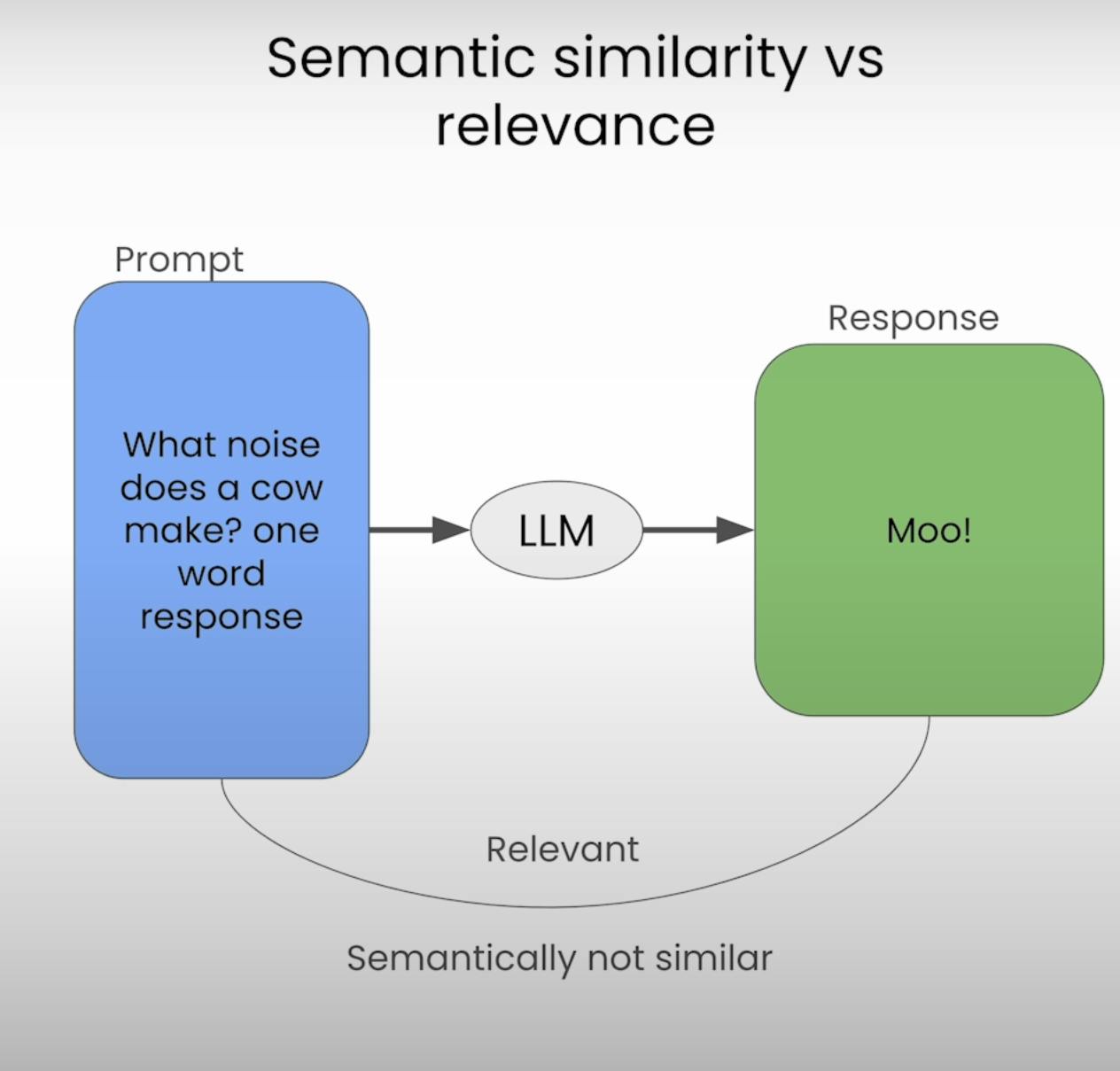
Response Self-Similarity
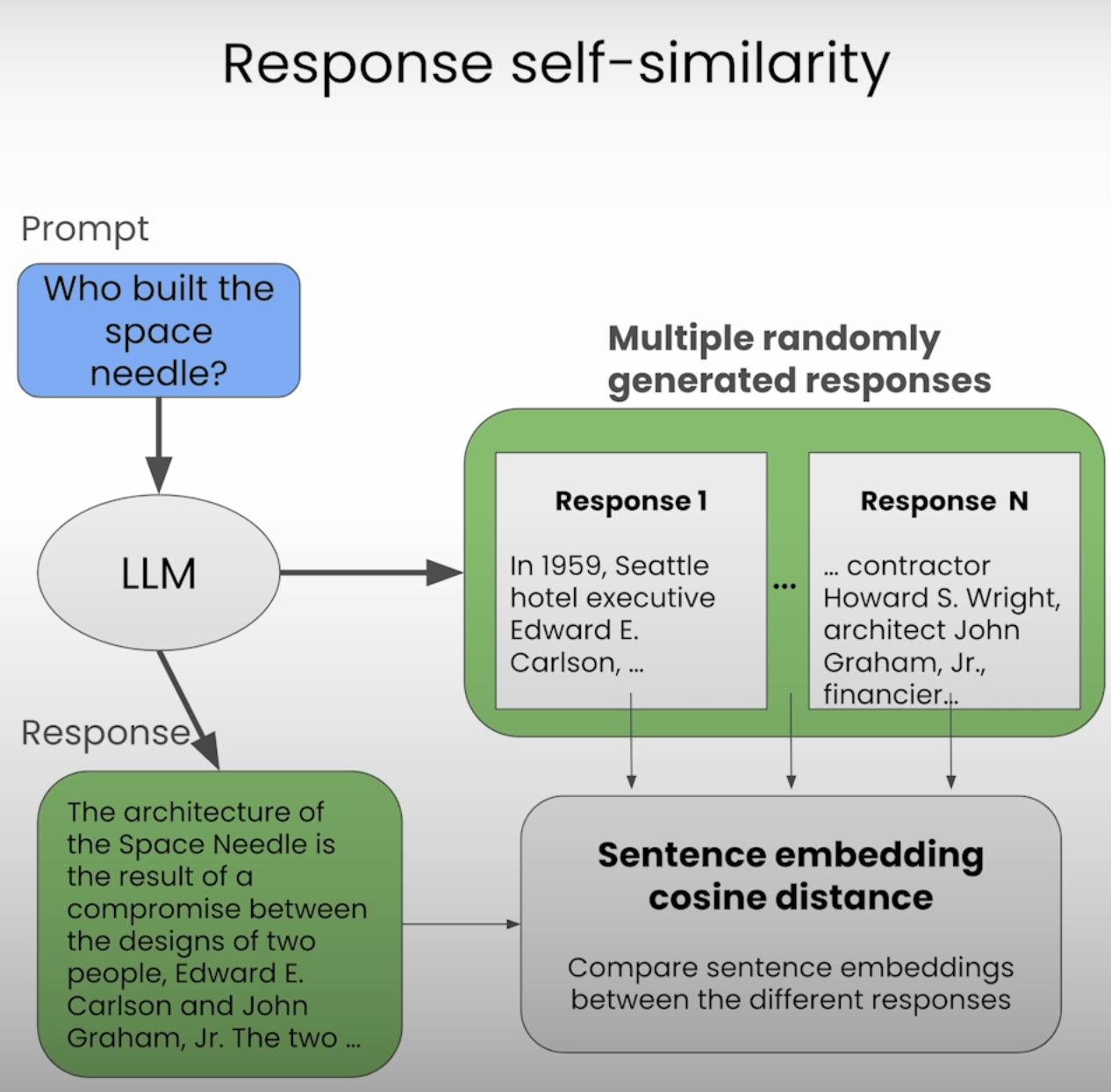
While comparing prompts and responses can provide valuable insights, the true strength of hallucination detection lies in comparing multiple responses generated by the same LLM for a given prompt. This approach, known as response self-similarity, allows us to evaluate the consistency and coherence of the LLM's outputs.
To calculate response self-similarity, we use sentence embeddings, which represent the meaning of entire sentences or passages rather than individual words. By computing the cosine distance between the sentence embeddings of the original response and those of additional responses, we can quantify the degree of similarity between them.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
response1 = "Hallucinations in data represent inaccurate or irrelevant responses to prompts..."
response2 = "Hallucinations occur when an LLM generates responses that are irrelevant or factually incorrect."
response3 = "Hallucinations are a phenomenon where LLMs produce outputs that are unrelated to the input prompt."
embedding1 = model.encode(response1)
embedding2 = model.encode(response2)
embedding3 = model.encode(response3)
from whylogs.util import WhyLogs
from whylogs.metrics import SentenceEmbeddingSelfSimilarity
wl = WhyLogs()
@wl.register_metric("response_self_similarity")
def response_self_similarity(text):
embeddings = [
model.encode(text["response"]),
model.encode(text["response2"]),
model.encode(text["response3"])
]
similarities = []
for i in range(1, len(embeddings)):
similarities.append(util.cos_sim(embeddings[0], embeddings[i]))
return [sum(similarities) / len(similarities)]
annotated_chats = wl.applyUDFsFromSchema(CHATS_DATASET)
annotated_chats[annotated_chats["response_self_similarity"] < 0.8].head(10)
By visualizing the response self-similarity score distribution and analyzing low-scoring examples, we can identify instances where the LLM's responses diverge significantly from each other, potentially indicating hallucinations or inconsistencies in the model's outputs.
LLM Self-Evaluation
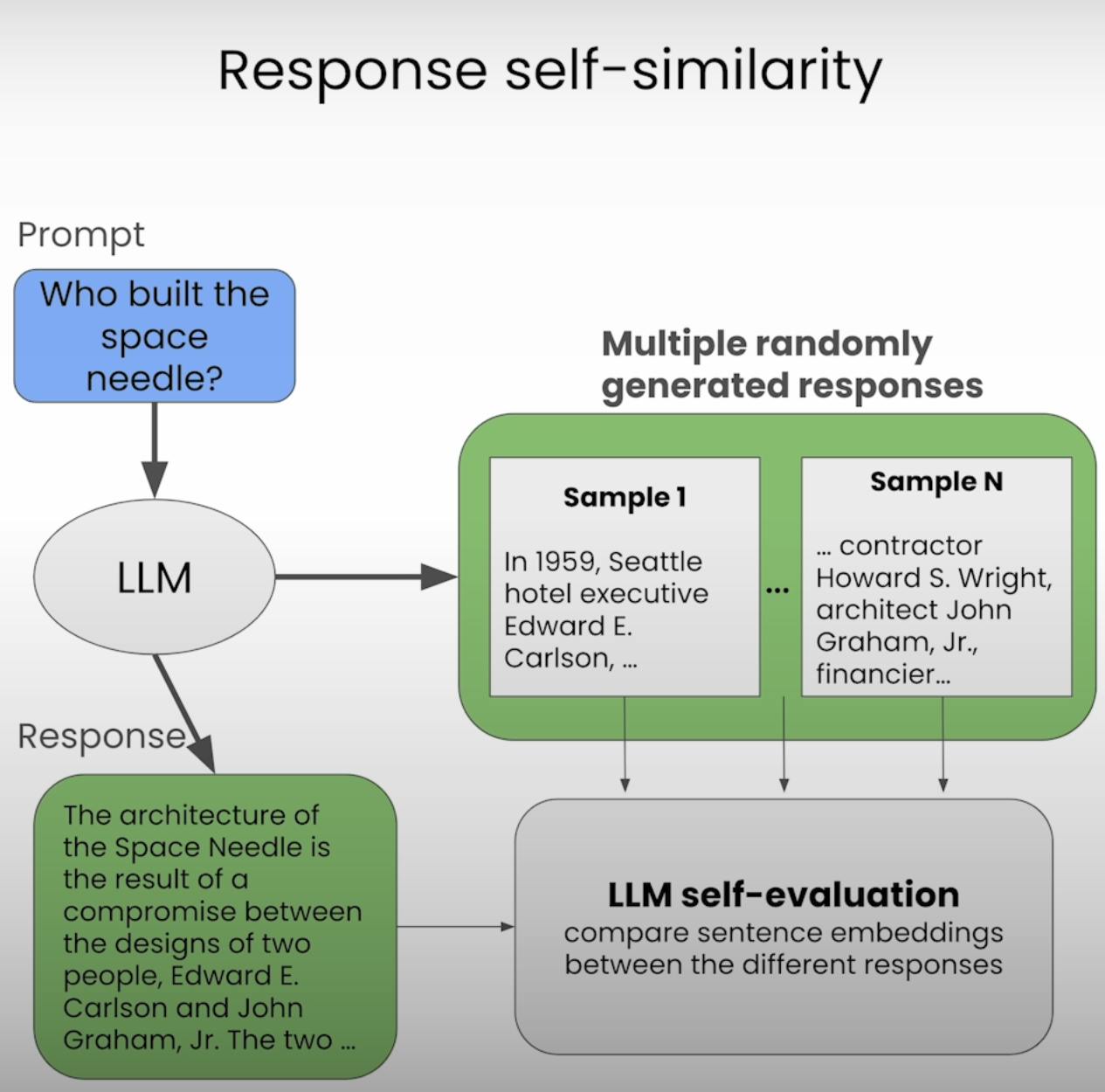
While the previous metrics rely on predefined algorithms and models to evaluate text similarity, we can also leverage the power of LLMs themselves to assess the consistency and similarity of their responses. This approach, known as LLM self-evaluation, involves prompting the LLM to evaluate the coherence and relevance of its own outputs.
To prompt the LLM for self-evaluation, we can craft a prompt that presents the different responses and asks the model to rate their consistency or similarity. Here's an example:
import openai
def llm_self_similarity(data, index):
prompt = f"""
Context: {data.loc[index, 'prompt']}
Response 1: {data.loc[index, 'response']}
Response 2: {data.loc[index, 'response2']}
Response 3: {data.loc[index, 'response3']}
Rate the consistency of Response 1 with the provided context (Responses 2 and 3) on a scale from 0 to 1, where 0 means completely inconsistent, and 1 means completely consistent.
"""
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
max_tokens=100,
n=1,
stop=None,
temperature=0.7,
)
return response.choices[0].text.strip()
wl = WhyLogs()
@wl.register_metric("prompted_self_similarity")
def prompted_self_similarity(text):
return [float(llm_self_similarity(text, text.name))]
annotated_chats = wl.applyUDFsFromSchema(CHATS_DATASET)
annotated_chats[annotated_chats["prompted_self_similarity"] < 0.8].head(10)
By prompting the LLM to evaluate the consistency and similarity of its responses, we can use its language understanding capabilities to identify potential hallucinations or inconsistencies. However, it's important to note that obtaining consistent responses from LLMs can be challenging, as the model's interpretation of the prompt may vary.
One potential improvement to this approach is to ask the LLM to evaluate specific sentences or aspects of the responses, rather than providing a single numerical score.
Conclusion
So, we have explored multiple of approaches to detect LLM hallucinations. We saw BLEU score and BERT embeddings, also we've dived deep into the details of text similarity metrics, uncovering their strengths and limitations. Later we say self-similarity, in order to use LLMs to evaluate their own outputs, and went through the challenges of obtaining calibrated and consistent responses.